
تقنيات النسخ: هي التقنيات المستخدمة لدراسة نسخة الكائن الحي، وهي مجموعة نسخ الحمض النووي الريبي (RNA) الخاصة به. يتم تسجيل محتوى المعلومات للكائن الحي في الحمض النووي لجينومه ويتم التعبير عنه من خلال النسخ. هنا يعمل (mRNA) كجزيء وسيط عابر في شبكة المعلومات بينما تؤدي (RNAs) الغير مشفرة وظائف متنوعة إضافية. تعمل التقنية على أخذ لقطة من النص في وقت إجمالي النصوص الموجودة في الخلية.
توفر تقنيات النسخ على نطاق واسع العمليات الخلوية النشطة والخاملة. يكمن التحدي الرئيسي في علم الأحياء الجزيئي في فهم كيف يمكن أن يؤدي نفس الجينوم إلى ظهور أنواع مختلفة من الخلايا وكيف يتم تنظيم التعبير الجيني. بدأت المحاولات الأولى لدراسة النصوص الكاملة في بداية التسعينيات، حيث أدت التطورات التكنولوجية اللاحقة منذ أواخر التسعينيات إلى تغيير المجال بشكل مستمر، وجعلت مجال تقنيات النسخ تخصصًا واسع الانتشار في العلوم البيولوجية. هناك نوعان من التقنيات المعاصرة الرئيسية في هذا المجال: المصفوفات الدقيقة ، وهي التي تحدد مجموعة من المتواليات المحددة مسبقًا، و (RNA-Seq) ، التي تستخدم التسلسل عالي الإنتاجية لتسجيل جميع النصوص. مع تطور التكنولوجيا، زاد حجم البيانات التي تنتجها كل تجربة نسخ. نتيجة لذلك، تم تكييف طرق تحليل البيانات بشكل طردي لتحليل كميات كبيرة بشكل متزايد من البيانات حيث تكون أكثر دقة وكفاءة. نمت قواعد بيانات النسخ وزادت فائدتها مع جمع المزيد من النسخ النصية ومشاركتها من قبل الباحثين. سيكون من المستحيل تقريبًا تفسير المعلومات الواردة في النسخة النصية بدون السيرعلى سياق التجارب السابقة.
إن قياس التعبير عن جينات الكائن الحي في الأنسجة أو الظروف والأوقات المختلفة، يعطي معلومات حول كيفية تنظيم الجينات ويكشف عن تفاصيل بيولوجيا الكائن الحي. يمكن استخدامه أيضًا لاستنتاج وظائف الجينات التي لم يتم توضيحها مسبقًا. مكّن تحليل تقنيات النسخ من دراسة كيفية تغير التعبير الجيني في الكائنات الحية المختلفة وكان له دور فعال في فهم الأمراض التي تصيب الإنسان. يسمح تحليل التعبير الجيني في مجمله باكتشاف اتجاهات منسقة واسعة لا يمكن تمييزها بمقايسات أكثر استهدافًا.
تاريخ تقنيات النسخ
تميز علم النسخ أنه أعاد صياغة ما هو ممكن في كل عقد وزمن، وجعلت التقنيات السابقة عفا عليها الزمن. نُشرت المحاولة الأولى لالتقاط نسخة جزئية من نسخة بشرية في عام 1991 وأبلغت عن وجود (609) تسلسل من (mRNA) من الدماغ البشري. في عام 2008 ، تم نشر نسختين بشريتين، مؤلفة من ملايين التسلسلات المشتقة من النسخ والتي تغطي (16000) جينًا، وبحلول عام 2015 تم نشر النسخ لمئات الأفراد. يتم الآن بشكل روتيني إنشاء نسخ من حالات المرض المختلفة أو الأنسجة أو حتى الخلايا المفردة. هذا التطور الكبير في علم النسخ ما كان إلا نتاج تطور التكنولوجيا الحديثة بشكل دقيق ونمو الاقتصاد بشكل ملحوظ وكبير. ما قبل تقنيات النسخ:
تم إجراء دراسات على النصوص الفردية قبل عدة سنوات من ظهورمنهج تقنيات النسخ. تم جمع مكتبات نصوص (silkmoth mRNA) وتحويلها إلى حمض نووي تكميلي (cDNA) للتخزين باستخدام النسخ العكسي في أواخر السبعينيات. أما في الثمانينيات، تم استخدام التسلسل منخفض الإنتاجية باستخدام طريقة (Sanger) لتسلسل النصوص العشوائية، وإنتاج علامات تسلسل معبر عنها بصيغة (ESTs) (expressed sequence tags). كانت طريقة (Sanger) للتسلسل سائدة حتى ظهور طرق عالية الإنتاجية مثل التسلسل بالتوليف (Solexa / Illumina). برزت (ESTs) خلال التسعينيات كطريقة فعالة لتحديد المحتوى الجيني للكائن الحي دون تسلسل الجينوم بأكمله. تم قياس كميات النصوص الفردية باستخدام النشاف الشمالي، ومصفوفات غشاء النايلون، وأساليب النسخ العكسي الكمي (PCR ،RT-qPCR) لاحقًا، ولكن هذه الطرق شاقة ويمكنها فقط التقاط قسم فرعي صغير من النسخة. وبالتالي، فإن الطريقة التي يتم بها التعبير عن النص ككل وتنظيمه ظلت غير معروفة حتى تم تطوير تقنيات إنتاجية أعلى وأكثر فعالية.
التجارب الحديثة
تم استخدام كلمة «ترانسكريبتوم» التي تعني تقنيات التسخ لأول مرة في التسعينيات. في عام 1995 ، تم تطوير واحدة من أقدم طرق النسخ المستندة إلى التسلسل، وهي التحليل التسلسلي للتعبير الجيني (SAGE) (serial analysis of gene expression)، والتي عملت من خلال تسلسل سانجر (Sanger sequencing) لشظايا النسخ العشوائية المتسلسلة. تم تحديد النصوص من خلال مطابقة الأجزاء مع الجينات المعروفة. تم أيضًا استخدام متغير من (SAGE) باستخدام تقنيات التسلسل عالية التطور والإنتاجية يسمى بالتحليل التعبير الجيني الرقمي ، لفترة وجيزة. ومع ذلك، فقد تم تجاوز هذه الأساليب إلى حد كبير من خلال التسلسل عالي الإنتاجية للنصوص الكاملة، والتي قدمت معلومات إضافية حول بنية النص مثل متغيرات لصق وغيره.
تطور التقنيات المعاصرة
| RNA- تسلسل | المصفوفات الدقيقة (microarray) | |
|---|---|---|
| الإنتاجية | من يوم واحد إلى أسبوع واحد لكل تجربة | يوم إلى يومين لكل تجربة |
| كمية إدخال RNA | منخفض ~ 1 نانوغرام إجمالي الحمض النووي الريبي | عالية ~ 1 ميكروغرام مرنا |
| كثافة اليد العاملة | مرتفع (تحضير العينات وتحليل البيانات) | منخفض |
| علم مسبق | لا شيء مطلوب، على الرغم من أن تسلسل الجينوم / النسخ المرجعي مفيد | مطلوب جينوم مرجعي / نسخة لتصميم المجسات |
| دقة الكميات | ~ 90٪ (مقيدة بالتغطية التسلسلية) | > 90٪ (مقيدة بدقة الكشف عن التألق) |
| دقة التسلسل | يمكن لـ RNA-Seq اكتشاف تعدد الأشكال ومتغيرات لصق (محدودة بدقة تسلسل تصل إلى 99٪ تقريبًا) | يمكن للمصفوفات المتخصصة اكتشاف متغيرات لصق الرنا المرسال (مقيدة بتصميم المجس والتهجين المتبادل) |
| حساسية | نص واحد لكل مليون (تقريبي، محدود بتغطية التسلسل) | نص واحد لكل ألف (تقريبي، محدود باكتشاف التألق) |
| مدى ديناميكي | 100000: 1 (محدود بتغطية التسلسل) | 1000: 1 (محدود بالتشبع الفلوري) |
| استنساخ التقنية | > 99٪ | > 99٪ |
تم تطوير التقنيات المعاصرة السائدة، المصفوفات الدقيقة (microarrays) و تسلسل RNA ، في منتصف التسعينيات والعقد الأول من القرن الحادي والعشرين. تم نشر المصفوفات الدقيقة التي تقيس وفرة مجموعة محددة من النصوص من خلال تهجينها إلى مجموعة من المجسات التكميلية لأول مرة في عام (1995). سمحت تقنية المصفوفات الدقيقة بفحص آلاف النسخ في وقت واحد وبتكلفة مخفضة بشكل كبير لكل جين وتوفير الأيدي العاملة. كانت كل من مصفوفات أليغنوكليوتيد المرقطة (spotted oligonucleotide arrays) ومصفوفات أفيميتريكس (Affymetrix) عالية الكثافة هي الطريقة الفضلى للتنميط النسخي حتى أواخر العقد الأول من القرن الحادي والعشرين. خلال هذه الفترة، تم إنتاج مجموعة من المصفوفات الدقيقة لتغطية الجينات المعروفة في الكائنات الحية النموذجية أو ذات الأهمية الاقتصادية. أدى التقدم في تصميم وتصنيع المصفوفات إلى تحسين خصوصية المجسات والسماح باختبار المزيد من الجينات على مجموعة واحدة. أدى التقدم في الكشف عن التألق إلى زيادة دقة وحساسية القياس النصوص ذات الوفرة المنخفضة.
يتم إنشاء تسلسل RNA عن طريق النسخ العكسي لـ كلًا من RNA و وتسلسل (cDNAs) الناتجة في المختبر يتم اشتقاق وفرة النسخ الناتجة من عدد التهم من كل نص. لذلك فقد تأثرت هذه التقنية بشكل كبير بتطوير تقنيات التسلسل عالية الإنتاجية . كان تسلسل التوقيع المتوازي (MPSS) مثالًا مبكرًا يعتمد على توليد من 16-20 متواليات bp عبر سلسلة معقدة من التهجين، واستخدمت في عام (2004) للتحقق من صحة التعبير عن عشرة آلاف جين في (Arabidopsis thaliana) . تم نشر أقدم عمل لتسلسل RNA في عام 2006 مع مائة ألف نسخة متسلسلة باستخدام تقنية 454 . كانت هذه تغطية كافية لتحديد وفرة النسخ النسبية. بدأت شعبية RNA-Seq في الزيادة بعد عام 2008 عندما سمحت تقنيات Solexa / Illumina الجديدة بتسجيل مليار تسلسل نسخ. يسمح هذا العائد الآن بتحديد ومقارنة النسخ البشرية.
جمع البيانات
يمكن توليد البيانات عن نصوص الحمض النووي الريبي (mRNA) من خلال واحد من مبدأين مهمين: تسلسل النصوص الفردية ( ESTs ، أو RNA-Seq) أو تهجين النصوص إلى مجموعة مرتبة من تحقيقات النيوكليوتيدات (المصفوفات الدقيقة) (microarray).
عزل الحمض النووي الريبي mRNA
تتطلب جميع طرق النسخ أن يتم عزل RNA أولاً عن الكائن التجريبي قبل تسجيل النصوص. على الرغم من أن الأنظمة البيولوجية متنوعة بشكل لا يصدق، فإن تقنيات استخراج الحمض النووي الريبي متشابهة إلى حد كبير وتتضمن التعطيل الميكانيكي للخلايا أو الأنسجة، وتعطيل RNase بأملاح متقلبة، اضطراب الجزيئات الكبيرة والمجمعات النوكليوتيدية المعقدة، وفصل الحمض النووي الريبي عن الجزيئات الحيوية غير المرغوب فيها بما في ذلك الحمض النووي DNA، والتركيز من الحمض النووي الريبي عن طريق الترسيب من المحلول أو الشطف من مصفوفة صلبة . يمكن أيضًا معالجة الحمض النووي الريبي المعزول باستخدام الدناز لهضم أي آثار للحمض النووي. من الضروري إثراء الحمض النووي الريبي المرسال لأن مستخلصات الحمض النووي الريبي الكلية عادة ما تكون 98٪ من الحمض النووي الريبوزي . يمكن إجراء الإثراء للنصوص بواسطة طرق تقارب poly-A أو عن طريق استنفاد RNA الريبوسومي باستخدام تحقيقات خاصة بالتسلسل. قد يؤثر الحمض النووي الريبي المتدهور أو الشائب على نتائج المصب ؛ على سبيل المثال، سيؤدي تخصيب mRNA من العينات المتدهورة إلى استنفاد 5 'نهايات mRNA وإشارة غير متساوية عبر طول النص. يعد التجميد المفاجئ للأنسجة قبل عزل الحمض النووي الريبي أمرًا نموذجيًا، ويتم الحرص على تقليل التعرض لإنزيمات RNase بمجرد اكتمال العزل.
علامات التسلسل المعبر عنها
علامة التسلسل المعبر عنها (EST) هي تسلسل نيوكليوتيد قصير يتم إنشاؤه من نسخة واحدة من RNA. يتم نسخ الحمض النووي الريبي (RNA) أولاً على أنه DNA تكميلي (cDNA) بواسطة إنزيم النسخ العكسي قبل تسلسل cDNA الناتج. نظرًا لأنه يمكن جمع ESTs دون معرفة مسبقة بالكائن الحي الذي أتت منه، فيمكن صنعها من خليط من الكائنات الحية أو العينات البيئية. على الرغم من استخدام طرق الإنتاجية العالية الآن، إلا أن مكتبات EST تقدم معلومات تسلسل لتصميمات المصفوفات الدقيقة المبكرة ؛ على سبيل المثال، تم تصميم ميكروأري الشعير من 350.000 EST متسلسلة مسبقًا.
التحليل التسلسلي والغطاء للتعبير الجيني (SAGE / CAGE)

كان التحليل( التسلسلي للتعبير الجيني (SAGE) تطويرًا لمنهجية EST لزيادة إنتاجية العلامات التي تم إنشاؤها والسماح بدخول بعض التقدير الكمي لوفرة النص.cDNA يتم توليدها من الحمض النووي الريبي mRNA ولكن بعد ذلك يتم هضمها إلى 11 pp tag باستخدام إنزيمات التقييد التي تقطع الحمض النووي في تسلسل معين، و 11 زوج من القاعدة على طول هذا التسلسل. بعد ذلك يتم ضم cDNA في سلاسل (> 500 bp) ومتسلسلة باستخدام طرق منخفضة، ولكن قراءة طويلة المدى مثل تسلسل Sanger . ثم يتم تقسيم التسلسلات مرة أخرى إلى علامات 11 نقطة أساس باستخدام برامج الكمبيوتر في عملية تسمى deconvolution . إذا كان الجينوم المرجعي متاحًا، فقد تتطابق هذه العلامات مع الجين المقابل في الجينوم. إذا كان الجينوم المرجعي غير متاح، فيمكن استخدام العلامات مباشرة كعلامات تشخيصية إذا وجد أنه يتم التعبير عنها بشكل مختلف في حالة المرض.
مصطلح التعبير الجيني لتحليل الغطاء (CAGE) هي أحد أشكال SAGE التي تسلسل العلامات من نهاية 5 ' من نسخة mRNA فقط. لذلك، يمكن تحديد موقع بدء نسخ الجينات عند محاذاة العلامات إلى جينوم مرجعي. يعد تحديد مواقع بدء الجينات مفيدًا لتحليل المروج واستنساخ cDNAs كاملة الطول.
تنتج طرق كلًا من SAGE و CAGE معلومات عن جينات أكثر مما كان ممكنًا في السابق عند تسلسل ESTs الفردية، ولكن تحضير العينات وتحليل البيانات عادة ما يكونان أكثر كثافة في العمل.
المصفوفات الدقيقة
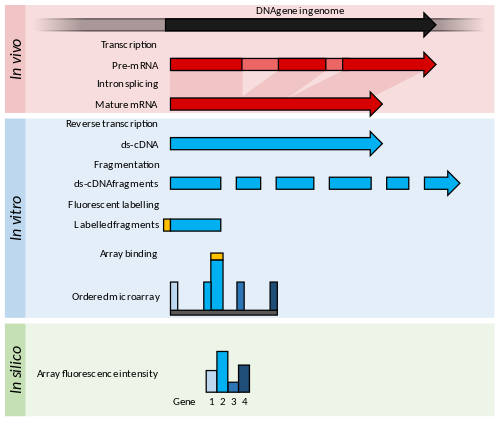
المبادئ والتطورات
تتكون المصفوفات الدقيقة من أوليغومرات نيوكليوتيد قصيرة، تُعرف باسم «المجسات» ، والتي يتم ترتيبها عادةً في شبكة على شريحة زجاجية. يتم تحديد وفرة نسخة عن طريق تهجين النصوص المسمى فلوريسنتلي لهذه التحقيقات. تشير شدة التألق في كل موقع مسبار على الصفيف إلى وفرة النسخ لتسلسل التحقيق هذا.
تتطلب المصفوفات الدقيقة بعض المعرفة الجينومية من الكائن الحي محل الاهتمام، على سبيل المثال، في شكل تسلسل الجينوم المشروح، أو مكتبة من ESTs التي يمكن استخدامها لإنشاء تحقيقات للمصفوفة.
طرق
عادةً ما تندرج المصفوفات الدقيقة الخاصة بالنسخ في إحدى فئتين عريضتين: المصفوفات المرقطة منخفضة الكثافة أو المصفوفات القصيرة عالية الكثافة. يتم الاستدلال على وفرة النسخ من شدة التألق المستمدة من النصوص ذات العلامات الفلورية التي ترتبط بالمصفوفة.
تتميز المصفوفات ذات الكثافة المنخفضة المرقطة عادةً بقطرات بيكوليتر لمجموعة من cDNAs المنقى والمصفوفة على سطح شريحة زجاجية. هذه المجسات أطول من تلك الخاصة بالمصفوفات عالية الكثافة ولا يمكنها تحديد أحداث الربط البديلة . تستخدم المصفوفات المرقطة نوعين مختلفين من الفلوروفور لتسمية عينات الاختبار والتحكم، وتستخدم نسبة التألق لحساب مقياس نسبي للوفرة. تستخدم المصفوفات عالية الكثافة تسمية فلورية واحدة، ويتم تهجين كل عينة واكتشافها على حدة. وقد شاع صفائف عالية الكثافة من قبل Affymetrix GeneChip مجموعة، حيث يتم كميا كل محضر من قبل العديد من القصير 25 -mer تحقيقات أن معا مقايسة جين واحد.
كانت صفائف NimbleGen عبارة عن مصفوفة عالية الكثافة تم إنتاجها بواسطة طريقة الكيمياء الضوئية بدون قناع، والتي سمحت بتصنيع مرن للمصفوفات بأعداد صغيرة أو كبيرة. كانت هذه المصفوفات تحتوي على 100000s من 45 إلى 85 مير وتم تهجينها بعينة ذات لون واحد لتحليل التعبير. تضمنت بعض التصميمات ما يصل إلى 12 مصفوفة مستقلة لكل شريحة.
تسلسل RNA

المبادئ والتطورات
يشير RNA-Seq إلى مزيج من منهجية التسلسل عالية الإنتاجية مع الأساليب الحسابية لالتقاط وقياس النصوص الموجودة في مستخلص الحمض النووي الريبي. يبلغ طول تسلسل النوكليوتيدات الناتج حوالي 100 نقطة أساس، ولكن يمكن أن يتراوح من 30 نقطة أساس إلى أكثر من 10000 نقطة أساس اعتمادًا على طريقة التسلسل المستخدمة. يستفيد RNA-Seq من أخذ عينات عميقة للنسخة مع العديد من الأجزاء القصيرة من نسخة للسماح بإعادة البناء الحسابي لنسخة RNA الأصلية عن طريق محاذاة القراءات مع جينوم مرجعي أو مع بعضها البعض ( تجميع de novo ). يمكن قياس كمية الرنا منخفضة الوفرة وعالية الوفرة في تجربة RNA-Seq ( نطاق ديناميكي من 5 أوامر من حيث الحجم ) - وهي ميزة رئيسية على نسخ المصفوفات الدقيقة. بالإضافة إلى ذلك، فإن كميات إدخال الحمض النووي الريبي (RNA) أقل بكثير بالنسبة لـ RNA-Seq (كمية نانوجرام) مقارنة بالمصفوفات الدقيقة (كمية ميكروغرام) ، مما يسمح بفحص أدق للهياكل الخلوية وصولاً إلى مستوى الخلية المفردة عند دمجها مع التضخيم الخطي لـ cDNA. من الناحية النظرية، لا يوجد حد أعلى للقياس الكمي في RNA-Seq ، وضوضاء الخلفية منخفضة جدًا لقراءات 100 نقطة أساس في المناطق غير المتكررة.
يمكن استخدام RNA-Seq لتحديد الجينات داخل الجينوم ، أو تحديد الجينات النشطة في نقطة زمنية معينة، ويمكن استخدام أعداد القراءة لنمذجة مستوى التعبير الجيني النسبي بدقة. لقد تحسنت منهجية RNA-Seq باستمرار، في المقام الأول من خلال تطوير تقنيات تسلسل الحمض النووي لزيادة الإنتاجية والدقة وطول القراءة. منذ الأوصاف الأولى في عامي 2006 و 2008 ، تم اعتماد RNA-Seq بسرعة وتجاوز المصفوفات الدقيقة باعتبارها تقنية النسخ السائدة في عام 2015.
أدى البحث عن بيانات النسخ على مستوى الخلايا الفردية إلى حدوث تقدم في أساليب إعداد مكتبة RNA-Seq ، مما أدى إلى تطورات مثيرة في الحساسية. يتم الآن وصف نسخ الخلية المفردة بشكل جيد وقد تم تمديدها إلى RNA-Seq في الموقع حيث يتم استجواب نسخ الخلايا الفردية مباشرة في الأنسجة الثابتة .
طرق
تم إنشاء RNA-Seq بالتنسيق مع التطور السريع لمجموعة من تقنيات تسلسل الحمض النووي عالية الإنتاجية. ومع ذلك، قبل تسلسل نسخ RNA المستخرجة، يتم تنفيذ عدة خطوات معالجة رئيسية. تختلف الطرق في استخدام إثراء النص، والتجزئة، والتضخيم، والتسلسل الفردي أو المزدوج، وما إذا كان يجب الحفاظ على معلومات الخيوط.
يمكن زيادة حساسية تجربة RNA-Seq عن طريق إثراء فئات من الحمض النووي الريبي (RNA) ذات الأهمية واستنفاد الحمض النووي الريبي المعروف الوفير. يمكن فصل جزيئات mRNA باستخدام تحقيقات oligonucleotides التي تربط ذيول poly-A الخاصة بها . بدلا من ذلك، RIBO استنفاد يمكن استخدامها لإزالة تحديدا وفيرة ولكن غير المفيدة الرنا الريباسي (rRNAs) من خلال التهجين لتحقيقات مصممة خصيصا ل الأصنوفة في تسلسل الريباسي محددة (على سبيل المثال الثدييات الريباسي، مصنع الريباسي). ومع ذلك، يمكن أن يؤدي استنفاد الضلع أيضًا إلى بعض التحيز عبر الاستنفاد غير المحدد للنصوص غير المستهدفة. يمكن تنقية RNAs الصغيرة، مثل micro RNAs ، بناءً على حجمها عن طريق الرحلان الكهربائي للهلام والاستخراج.
نظرًا لأن mRNAs أطول من أطوال القراءة الخاصة بأساليب التسلسل عالية الإنتاجية النموذجية، يتم عادةً تجزئة النصوص قبل التسلسل. تعد طريقة التجزئة جانبًا رئيسيًا في بناء مكتبة التسلسل. يمكن تحقيق التجزئة عن طريق التحليل المائي الكيميائي ، أو الإرذاذ، أو الصوتنة، أو النسخ العكسي باستخدام نيوكليوتيدات متسلسلة . بدلاً من ذلك، يمكن إجراء التجزئة وعلامات (كدنا) في وقت واحد باستخدام إنزيمات ترانسبوزيز .
أثناء التحضير للتسلسل، يمكن تضخيم نسخ (كدنا) من النصوص بواسطة تفاعل البوليميراز المتسلسل لإثراء الأجزاء التي تحتوي على تسلسل المحول المتوقع 5 'و 3'. يستخدم التضخيم أيضًا للسماح بتسلسل كميات إدخال منخفضة جدًا من RNA ، وصولاً إلى أقل من 50 بيكوغرام في التطبيقات المتطرفة. يمكن استخدام ضوابط الزيادة في RNAs المعروفة لتقييم مراقبة الجودة للتحقق من إعداد المكتبة وتسلسلها، من حيث محتوى GC ، وطول الجزء، بالإضافة إلى التحيز بسبب موضع التجزئة داخل النص. المعرّفات الجزيئية الفريدة (UMIs) عبارة عن تسلسلات عشوائية قصيرة تُستخدم لتمييز أجزاء التسلسل بشكل فردي أثناء إعداد المكتبة بحيث يكون كل جزء مميز فريدًا. توفر UMIs مقياسًا مطلقًا للتقدير الكمي، وفرصة لتصحيح تحيز التضخيم اللاحق الذي تم تقديمه أثناء إنشاء المكتبة، وتقدير حجم العينة الأولي بدقة. تعتبر UMIs مناسبة بشكل خاص لنسخة RNA-Seq أحادية الخلية، حيث يتم تقييد كمية إدخال الحمض النووي الريبي (RNA) والتضخيم الموسع للعينة مطلوبًا.
بمجرد أن يتم تحضير جزيئات النص، يمكن تسلسلها في اتجاه واحد فقط (طرف واحد) أو كلا الاتجاهين (نهاية مزدوجة). عادةً ما يكون إنتاج التسلسل أحادي النهاية أسرع، وأرخص من التسلسل ثنائي النهاية وكافٍ لتقدير مستويات التعبير الجيني. ينتج عن التسلسل المزدوج النهاية محاذاة / تجميعات أكثر قوة، وهو أمر مفيد للتعليق التوضيحي للجينات واكتشاف الشكل الإسوي للنسخ. تحافظ أساليب RNA-Seq الخاصة بالجدار على معلومات حبلا لنسخة متسلسلة. بدون معلومات الخيط، يمكن محاذاة القراءات مع موضع الجين ولكن لا تخبر في أي اتجاه يتم نسخ الجين. يعد Stranded-RNA-Seq مفيدًا لفك تشفير النسخ للجينات التي تتداخل في اتجاهات مختلفة ولإجراء تنبؤات جينية أكثر قوة في الكائنات غير النموذجية.
| منصة | الافراج التجاري | طول القراءة النموذجي | أقصى سرعة لكل شوط | دقة قراءة واحدة | عمليات تشغيل RNA-Seq المودعة في NCBI SRA (أكتوبر 2016) |
|---|---|---|---|---|---|
| 454 علوم الحياة | 2005 | 700 بي بي | 0.7 جيجابت | 99.9٪ | 3548 |
| إلومينا | 2006 | 50 - 300 سنة مضت | 900 جيجابت | 99.9٪ | 362903 |
| صلب | 2008 | 50 زوجا | 320 جيجابت | 99.9٪ | 7032 |
| ايون تورنت | 2010 | 400 نقطة أساس | 30 جيجابت | 98٪ | 1953 |
| باكبيو | 2011 | 10000 نقطة أساس | 2 جيجابت | 87٪ | 160 |
يعتمد RNA-Seq حاليًا على نسخ جزيئات RNA إلى جزيئات cDNA قبل التسلسل ؛ لذلك، الأنظمة الأساسية اللاحقة هي نفسها بالنسبة للبيانات الجينية والنسخية. وبالتالي، كان تطوير تقنيات تسلسل الحمض النووي سمة مميزة لـ RNA-Seq. التسلسل المباشر للحمض النووي الريبي باستخدام التسلسل النانوي يمثل أحدث تقنيات RNA-Seq الحالية. يمكن للتسلسل النانوي للحمض النووي الريبي أن يكتشف القواعد المعدلة التي يمكن إخفاؤها بطريقة أخرى عند تسلسل cDNA وأيضًا يلغي خطوات التضخيم التي يمكن أن تؤدي إلى التحيز.
تعتمد حساسية ودقة تجربة RNA-Seq على عدد القراءات التي تم الحصول عليها من كل عينة. هناك حاجة إلى عدد كبير من القراءات لضمان التغطية الكافية للنسخة، مما يتيح الكشف عن النصوص منخفضة الوفرة. يزداد التصميم التجريبي تعقيدًا عن طريق تقنيات التسلسل ذات نطاق الإخراج المحدود، والكفاءة المتغيرة لإنشاء التسلسل، وجودة التسلسل المتغير. يضاف إلى هذه الاعتبارات أن كل نوع لديه عدد مختلف من الجينات وبالتالي يتطلب إنتاج تسلسل مخصص لنسخة فعالة. حددت الدراسات المبكرة عتبات مناسبة تجريبيًا، ولكن مع نضوج التكنولوجيا، تم التنبؤ بالتغطية المناسبة حسابياً عن طريق تشبع النسخ. الطريقة الأكثر فاعلية لتحسين الكشف عن التعبير التفاضلي في الجينات منخفضة التعبير هي إضافة المزيد من التكرارات البيولوجية بدلاً من إضافة المزيد من القراءات. المعايير الحالية التي أوصى بها مشروع Encyclopedia of DNA Elements (ENCODE) هي لتغطية الإكسوم 70 ضعفًا لمعيار RNA-Seq وتغطية exome تصل إلى 500 ضعف لاكتشاف النصوص والأشكال الإسوية النادرة.
تحليل البيانات
طرق النسخ متوازية للغاية وتتطلب حسابًا كبيرًا لإنتاج بيانات ذات مغزى لكل من تجارب ميكروأري و RNA-Seq. يتم تسجيل بيانات Microarray كصور عالية الدقة ، مما يتطلب اكتشاف الميزات والتحليل الطيفي. يبلغ حجم كل من ملفات الصور الأولية Microarray حوالي 750 ميجابايت، بينما يبلغ حجم الشدة المعالجة حوالي 60 ميجابايت. يمكن أن تكشف التحقيقات القصيرة المتعددة التي تتطابق مع نسخة واحدة عن تفاصيل حول بنية intron - exon ، مما يتطلب نماذج إحصائية لتحديد مصداقية الإشارة الناتجة. تنتج دراسات RNA-Seq المليارات من سلاسل الحمض النووي القصيرة، والتي يجب أن تتماشى مع الجينومات المرجعية المكونة من ملايين إلى مليارات أزواج القواعد. يتطلب تجميع القراءات <i id="mwApQ">De novo</i> داخل مجموعة البيانات إنشاء رسوم بيانية تسلسلية معقدة للغاية. عمليات RNA-Seq متكررة للغاية وتستفيد من الحساب المتوازي ولكن الخوارزميات الحديثة تعني أن أجهزة الحوسبة الاستهلاكية كافية لتجارب النسخ البسيطة التي لا تتطلب تجميعًا جديدًا للقراءات . يمكن التقاط نسخة بشرية بدقة باستخدام RNA-Seq مع 30 مليون تسلسل 100 نقطة أساس لكل عينة. قد يتطلب هذا المثال ما يقرب من 1.8 جيجا بايت من مساحة القرص لكل عينة عند تخزينها بتنسيق fastq مضغوط. ستكون بيانات العد المعالج لكل جين أصغر بكثير، أي ما يعادل شدة ميكروأري المعالجة. قد يتم تخزين بيانات التسلسل في مستودعات عامة، مثل أرشيف قراءة التسلسل (SRA). يمكن تحميل مجموعات بيانات RNA-Seq عبر Gene Expression Omnibus.
معالجة الصورة

يجب أن تحدد معالجة الصور بالميكروأري بشكل صحيح الشبكة العادية للميزات داخل صورة وأن تحدد بشكل مستقل شدة التألق لكل ميزة. بالإضافة إلى ذلك، يجب تحديد القطع الأثرية للصورة وإزالتها من التحليل العام. تشير شدة الإسفار مباشرة إلى وفرة كل تسلسل، حيث أن تسلسل كل مسبار في الصفيف معروف بالفعل.
تتضمن الخطوات الأولى لـ RNA-seq أيضًا معالجة صور مماثلة ؛ ومع ذلك، عادةً ما يتم التعامل مع تحويل الصور إلى بيانات متسلسلة تلقائيًا بواسطة برنامج الجهاز. ينتج عن طريقة تسلسل Illumina بالتخليق مجموعة من المجموعات الموزعة على سطح خلية التدفق. يتم تصوير خلية التدفق حتى أربع مرات خلال كل دورة تسلسل، مع عشرات إلى مئات الدورات في المجموع. تتشابه مجموعات خلايا التدفق مع بقع ميكروأري ويجب تحديدها بشكل صحيح خلال المراحل المبكرة من عملية التسلسل. في طريقة Roche للتسلسل الحراري ، تحدد شدة الضوء المنبعث عدد النيوكليوتيدات المتتالية في تكرار البوليمر المتجانس. هناك العديد من المتغيرات في هذه الطرق ، ولكل منها ملف تعريف خطأ مختلف للبيانات الناتجة.
تحليل بيانات تسلسل RNA
تولد تجارب RNA-Seq حجمًا كبيرًا من قراءات التسلسل الأولي التي يجب معالجتها للحصول على معلومات مفيدة. يتطلب تحليل البيانات عادةً مجموعة من أدوات برمجيات المعلوماتية الحيوية (انظر أيضًا قائمة أدوات المعلوماتية الحيوية RNA-Seq ) التي تختلف وفقًا للتصميم والأهداف التجريبية. يمكن تقسيم العملية إلى أربع مراحل: مراقبة الجودة والمحاذاة والتقدير والتعبير التفاضلي. يتم تشغيل معظم برامج RNA-Seq الشائعة من واجهة سطر الأوامر ، إما في بيئة Unix أو ضمن البيئة الإحصائية R / Bioconductor .
رقابة الجودة
قراءات التسلسل ليست مثالية ، لذلك يجب تقدير دقة كل قاعدة في التسلسل لتحليلات المصب. يتم فحص البيانات الأولية للتأكد من: درجات الجودة للمكالمات الأساسية عالية ، ومحتوى GC يطابق التوزيع المتوقع ، والزخارف المتسلسلة القصيرة ( k-mers ) ليست ممثلة بشكل زائد ، ومعدل تكرار القراءة منخفض بشكل مقبول. توجد عدة خيارات برمجية لتحليل جودة التسلسل ، بما في ذلك FastQC و FaQCs. يمكن إزالة التشوهات (التشذيب) أو تمييزها بمعاملة خاصة أثناء العمليات اللاحقة.
توضيح
من أجل ربط تسلسل قراءة الوفرة بالتعبير عن جين معين ، يتم محاذاة تسلسل النص إلى جينوم مرجعي أو <i id="mwAtc">دي نوفو</i> محاذي لبعضها البعض إذا لم يتوفر مرجع. تتضمن التحديات الرئيسية لبرمجيات المحاذاة سرعة كافية للسماح بمحاذاة مليارات من التسلسلات القصيرة في إطار زمني ذي مغزى ، والمرونة في التعرف على التضفير الداخلي للـ mRNA والتعامل معه ، والتخصيص الصحيح للقراءات التي تعينها على مواقع متعددة. عالجت التطورات البرمجية هذه المشكلات بشكل كبير ، كما أن الزيادات في طول قراءة التسلسل تقلل من فرصة محاذاة القراءة الغامضة. يحتفظ EBI بقائمة بمحاذاة التسلسل عالية الإنتاجية المتوفرة حاليًا.
تتطلب محاذاة تسلسلات mRNA للنسخة الأولية المشتقة من حقيقيات النوى إلى جينوم مرجعي معالجة متخصصة لتسلسلات intron ، والتي لا توجد في mRNA الناضج. تقوم أدوات محاذاة القراءة القصيرة بإجراء جولة إضافية من المحاذاة المصممة خصيصًا لتحديد الوصلات الملصقة ، ويتم إعلامها من خلال تسلسل موقع لصق الكنسي ومعلومات موقع لصق إنترون المعروفة. إن تحديد تقاطعات لصق intron يمنع القراءات من أن تكون غير محاذاة عبر تقاطعات الوصلات أو يتم التخلص منها بشكل خاطئ ، مما يسمح بمحاذاة المزيد من القراءات مع الجينوم المرجعي وتحسين دقة تقديرات التعبير الجيني. نظرًا لأن تنظيم الجينات قد يحدث على مستوى الشكل الإسوي للـ mRNA ، فإن المحاذاة الواعية للوصلة تسمح أيضًا بالكشف عن تغييرات وفرة الشكل الإسوي التي قد تُفقد في تحليل مجمّع.
يمكن استخدام تجميع De novo لمحاذاة القراءات مع بعضها البعض لإنشاء تسلسلات نصية كاملة الطول دون استخدام جينوم مرجعي. تشمل التحديات الخاصة بتجميع de novo متطلبات حسابية أكبر مقارنة بنسخة مرجعية ، والتحقق الإضافي من المتغيرات الجينية أو الأجزاء ، والشرح الإضافي للنصوص المجمعة. لقد ثبت أن المقاييس الأولى المستخدمة لوصف تجميعات النسخ ، مثل N50 ، مضللة وأن طرق التقييم المحسنة متاحة الآن. مقاييس تعتمد على الشرح وتقييم أفضل من اكتمال التجميع، مثل contig متبادلة أفضل ضرب العد. بمجرد تجميع de novo ، يمكن استخدام التجميع كمرجع لطرق محاذاة التسلسل اللاحقة وتحليل التعبير الجيني الكمي.
| البرمجيات | صدر | آخر تحديث | الكفاءة الحسابية | نقاط القوة والضعف |
|---|---|---|---|---|
| الواحات المخملية | 2008 | 2011 | متطلبات ذاكرة الوصول العشوائي منخفضة ، أحادية الخيوط ، عالية | مُجمّع القراءة القصيرة الأصلي. تم استبداله الآن إلى حد كبير. |
| سوابدينوفو ترانس | 2011 | 2014 | متطلبات ذاكرة الوصول العشوائي المعتدلة ومتعددة الخيوط والمتوسطة | مثال مبكر لمجمع قراءة قصيرة. تم تحديثه لتجميع النسخ. |
| Trans-ABySS | 2010 | 2016 | متطلبات ذاكرة الوصول العشوائي المعتدلة ومتعددة الخيوط والمتوسطة | مناسبة للقراءات القصيرة ، ويمكنها التعامل مع النسخ المعقدة ، ويتوفر إصدار MPI المتوازي لحوسبة المجموعات. |
| الثالوث | 2011 | 2017 | متطلبات ذاكرة الوصول العشوائي المعتدلة ومتعددة الخيوط والمتوسطة | مناسبة للقراءات القصيرة. يمكنه التعامل مع النسخ المعقدة ولكنها تتطلب ذاكرة مكثفة. |
| ميريست | 1999 | 2016 | متطلبات ذاكرة الوصول العشوائي المعتدلة ومتعددة الخيوط والمتوسطة | يمكن معالجة التسلسلات المتكررة ، والجمع بين تنسيقات التسلسل المختلفة ، ويتم قبول مجموعة واسعة من أنظمة التسلسل. |
| نيوبلير | 2004 | 2012 | متطلبات ذاكرة الوصول العشوائي منخفضة ، أحادية الخيط ، عالية | متخصص لاستيعاب أخطاء تسلسل البوليمر المتماثل النموذجي لمسلسلات Roche 454. |
| منضدة عمل علم الجينوم CLC | 2008 | 2014 | متطلبات ذاكرة الوصول العشوائي عالية ومتعددة الخيوط ومنخفضة | لديه واجهة مستخدم رسومية ، ويمكنه الجمع بين تقنيات التسلسل المتنوعة ، ولا يحتوي على ميزات خاصة بالنسخة ، ويجب شراء ترخيص قبل الاستخدام. |
| SPAdes | 2012 | 2017 | متطلبات ذاكرة الوصول العشوائي عالية ومتعددة الخيوط ومنخفضة | تستخدم لتجارب النسخ على الخلايا المفردة. |
| RSEM | 2011 | 2017 | متطلبات ذاكرة الوصول العشوائي عالية ومتعددة الخيوط ومنخفضة | يمكن تقدير تكرار النصوص المقسمة بشكل بديل. سهل الاستخدام. |
| StringTie | 2015 | 2019 | متطلبات ذاكرة الوصول العشوائي عالية ومتعددة الخيوط ومنخفضة | يمكن استخدام مزيج من طرق التجميع الموجه بالمرجع و de novo لتحديد النصوص. |
RAM - ذاكرة الوصول العشوائي ؛ MPI - واجهة تمرير الرسائل ؛ EST - علامة التسلسل المعبر عنها.
تحديد الكميات
يمكن إجراء التحديد الكمي لمحاذاة التسلسل على مستوى الجين أو إكسون أو نسخة. تتضمن المخرجات النموذجية جدولًا بأعداد القراءة لكل ميزة يتم توفيرها للبرنامج ؛ على سبيل المثال ، للجينات في ملف تنسيق ميزة عامة . يمكن حساب عدد قراءة الجينات والإكسون بسهولة تامة باستخدام HTSeq ، على سبيل المثال. يعتبر التحديد الكمي على مستوى النص أكثر تعقيدًا ويتطلب طرقًا احتمالية لتقدير وفرة النص الإسوي من معلومات القراءة القصيرة ؛ على سبيل المثال ، باستخدام برنامج أزرار الكم. يجب تحديد القراءات التي تتماشى جيدًا مع مواقع متعددة وإما إزالتها أو محاذاتها مع أحد المواقع المحتملة أو مواءمتها مع الموقع الأكثر احتمالًا.
يمكن لبعض طرق القياس الكمي الالتفاف على الحاجة إلى محاذاة دقيقة للقراءة إلى تسلسل مرجعي تمامًا. تجمع طريقة برنامج kallisto بين المحاذاة الزائفة والقياس الكمي في خطوة واحدة تعمل على تنفيذ 2 أوامر من حيث الحجم أسرع من الأساليب المعاصرة مثل تلك المستخدمة بواسطة برنامج tophat / cufflinks ، مع عبء حسابي أقل.
بمجرد توفر التعداد الكمي لكل نص ، يتم قياس التعبير الجيني التفاضلي عن طريق تطبيع البيانات والنمذجة والتحليل الإحصائي لها. ستقرأ معظم الأدوات جدولًا للجينات وتقرأ الأعداد كمدخلات لها ، لكن بعض البرامج ، مثل cuffdiff ، ستقبل تنسيق خريطة المحاذاة الثنائية كمدخلات. النواتج النهائية لهذه التحليلات هي قوائم الجينات المصحوبة باختبارات زوجية مرتبطة بالتعبير التفاضلي بين العلاجات وتقديرات احتمالية هذه الاختلافات.
| البرمجيات | بيئة | تخصص |
|---|---|---|
| Cuffdiff2 | يونكس | تحليل النسخ الذي يتتبع التضفير البديل لـ mRNA |
| EdgeR | R / موصل حيوي | أي بيانات الجينوم القائمة على العد |
| DEseq2 | R / موصل حيوي | أنواع بيانات مرنة ، تكرار منخفض |
| ليما / فوم | R / موصل حيوي | بيانات Microarray أو RNA-Seq ، تصميم تجربة مرن |
| ثوب الكرة | R / موصل حيوي | اكتشاف النصوص فعالة وحساسة ومرنة. |
mRNA - messenger RNA.
التحقق من الصحة
يمكن التحقق من صحة تحليلات النسخ باستخدام تقنية مستقلة ، على سبيل المثال ، PCR الكمي (qPCR) ، والتي يمكن التعرف عليها وتقييمها إحصائيًا. يتم قياس التعبير الجيني مقابل معايير محددة لكل من الجينات المعنية والجينات الضابطة . القياس بواسطة qPCR مشابه للقياس الذي حصل عليه RNA-Seq حيث يمكن حساب قيمة لتركيز المنطقة المستهدفة في عينة معينة. ومع ذلك ، فإن qPCR مقصور على amplicons أصغر من 300 نقطة أساس ، وعادةً ما تكون باتجاه الطرف 3 'من منطقة التشفير ، مع تجنب 3'UTR . إذا كان التحقق من صحة الأشكال الإسوية للنسخة مطلوبًا ، فيجب أن يشير فحص محاذاة قراءة RNA-Seq إلى المكان الذي يمكن فيه وضع بادئات qPCR للتمييز الأقصى. ينتج عن قياس جينات التحكم المتعددة جنبًا إلى جنب مع الجينات ذات الأهمية مرجعًا ثابتًا ضمن سياق بيولوجي. أظهر التحقق من صحة qPCR لبيانات RNA-Seq عمومًا أن طرق RNA-Seq المختلفة مترابطة بشكل كبير.
يعد التحقق الوظيفي للجينات الرئيسية من الاعتبارات المهمة للتخطيط بعد النسخ. قد تكون أنماط التعبير الجيني لوحظت ترتبط وظيفيا إلى النمط الظاهري عن طريق مستقلة تدق إلى أسفل / الإنقاذ الدراسة في الكائن الحي من الفائدة.
التطبيقات
التشخيص وتحديد ملامح المرض
شهدت استراتيجيات النسخ تطبيقًا واسعًا عبر مجالات متنوعة من البحوث الطبية الحيوية ، بما في ذلك تشخيص المرض والتنميط . سمحت مناهج RNA-Seq بالتعرف على نطاق واسع لمواقع بدء النسخ ، واستخدام المروج البديل غير المكشوف ، وتعديلات الربط الجديدة. هذه العناصر التنظيمية مهمة في مرض الإنسان ، وبالتالي ، فإن تحديد مثل هذه المتغيرات أمر بالغ الأهمية لتفسير دراسات ارتباط المرض . يمكن لـ RNA-Seq أيضًا تحديد تعدد أشكال النوكليوتيدات المفردة (SNPs) المرتبطة بالأمراض ، والتعبير الخاص بالأليل ، واندماج الجينات ، مما يساهم في فهم المتغيرات المسببة للمرض.
الينقولات الرجعية هي عناصر قابلة للنقل والتي تتكاثر داخل جينومات حقيقية النواة من خلال عملية تتضمن النسخ العكسي . يمكن أن يوفر RNA-Seq معلومات حول نسخ الينقولات العكسية الذاتية التي قد تؤثر على نسخ الجينات المجاورة بواسطة آليات جينية مختلفة تؤدي إلى المرض. وبالمثل، فإن إمكانية استخدام الحمض النووي الريبي تسلسل لفهم مرض المناعة ذات الصلة توسعا سريعا بسبب القدرة على تشريح السكان الخلايا المناعية وتسلسل الخلايا T و مستقبلات الخلايا B ذخيرة من المرضى.
النسخ البشرية وعوامل المسببات المرضية
أصبح RNA-Seq لمسببات الأمراض البشرية طريقة ثابتة لقياس تغيرات التعبير الجيني ، وتحديد عوامل الضراوة الجديدة ، والتنبؤ بمقاومة المضادات الحيوية ، وكشف النقاب عن التفاعلات المناعية للمضيف الممرض . الهدف الأساسي من هذه التقنية هو تطوير تدابير مكافحة العدوى المثلى والعلاج الفردي المستهدف.
ركز تحليل النسخ في الغالب على المضيف أو الممرض تم تطبيق Dual RNA-Seq لتشكيل تعبير RNA في وقت واحد في كل من الممرض والمضيف طوال عملية العدوى. تمكن هذه التقنية من دراسة الاستجابة الديناميكية وشبكات تنظيم الجينات بين الأنواع في كل من شركاء التفاعل من الاتصال الأولي وحتى الغزو والثبات النهائي للعامل الممرض أو التطهير بواسطة الجهاز المناعي المضيف.
استجابات البيئة
يسمح علم النسخ بتحديد الجينات والمسارات التي تستجيب للضغوط البيئية الحيوية وغير الحيوية وتتصدى لها . تسمح الطبيعة غير المستهدفة للنصوص بتحديد شبكات النسخ الجديدة في الأنظمة المعقدة. على سبيل المثال ، حدد التحليل المقارن لمجموعة من سلالات الحمص في مراحل نمو مختلفة ملامح نسخ متميزة مرتبطة بضغوط الجفاف والملوحة ، بما في ذلك تحديد دور الأشكال الإسوية للنسخة من AP2 - EREBP . التحقيق في التعبير الجيني خلال بيوفيلم تشكيل من الفطريات المسببة للمرض المبيضات البيض كشفت مجموعة المشترك المنظم للجينات حاسمة لإنشاء بيوفيلم والصيانة.
يوفر التنميط النسخي أيضًا معلومات مهمة حول آليات مقاومة الأدوية . حدد تحليل أكثر من 1000 عزلة من Plasmodium falciparum ، وهو طفيلي خبيث مسؤول عن الملاريا في البشر ، أن زيادة تنظيم استجابة البروتين غير المطوية والتقدم البطيء خلال المراحل المبكرة من دورة النمو اللاجنسي داخل الكريات الحمر ارتبطت بمقاومة الأرتيميسينين في العزلات من جنوب شرق آسيا .
شرح وظيفة الجينات
كانت جميع تقنيات النسخ مفيدة بشكل خاص في تحديد وظائف الجينات وتحديد المسؤولين عن أنماط ظاهرية معينة. Transcriptomics من نبات الأرابيدوبسيس الطرز البيئية التي المعادن hyperaccumulate ارتباطا الجينات المسؤولة عن امتصاص المعادن والتسامح و التوازن مع النمط الظاهري. تم استخدام تكامل مجموعات بيانات RNA-Seq عبر الأنسجة المختلفة لتحسين شرح وظائف الجينات في الكائنات الحية المهمة تجاريًا (مثل الخيار ) أو الأنواع المهددة (مثل الكوالا ).
لا تعتمد قراءة تجميع RNA-Seq على الجينوم المرجعي ولذا فهي مثالية لدراسات التعبير الجيني للكائنات غير النموذجية ذات الموارد الجينومية غير الموجودة أو ضعيفة التطور. على سبيل المثال ، تم إنشاء قاعدة بيانات لـ SNPs المستخدمة في برامج تربية دوغلاس التنوب عن طريق تحليل نسخة دي نوفو في غياب الجينوم المتسلسل . وبالمثل ، تم تحديد الجينات التي تعمل في تطوير أنسجة القلب والعضلات والعصبية في الكركند من خلال مقارنة الترانسكريبتومات لأنواع الأنسجة المختلفة دون استخدام تسلسل الجينوم. يمكن أيضًا استخدام RNA-Seq لتحديد مناطق ترميز البروتين غير المعروفة سابقًا في الجينوم المتسلسل الحالي.
الشيخوخة القائمة على النسخ
التدخلات الوقائية المتعلقة بالشيخوخة غير ممكنة بدون قياس سرعة الشيخوخة الشخصية. الطريقة الأحدث والأكثر تعقيدًا لقياس معدل الشيخوخة هي باستخدام المؤشرات الحيوية المتغيرة لشيخوخة الإنسان التي تعتمد على استخدام الشبكات العصبية العميقة التي يمكن تدريبها على أي نوع من البيانات البيولوجية omics للتنبؤ بعمر الموضوع. لقد ثبت أن الشيخوخة محرك قوي لتغييرات النسخ. عانت الساعات القديمة القائمة على النسخ من تباين كبير في البيانات ودقة منخفضة نسبيًا. ومع ذلك ، فإن النهج الذي يستخدم مقياسًا زمنيًا وثنائية الترانسكريبتومات لتحديد مجموعة الجينات التي تتنبأ بالعمر البيولوجي بدقة يسمح لها بالوصول إلى تقييم قريب من الحد النظري .
الحمض النووي الريبي الغير مشفر
يتم تطبيق Transcriptomics بشكل شائع على محتوى mRNA للخلية. ومع ذلك ، فإن نفس التقنيات قابلة للتطبيق بشكل متساوٍ على RNAs غير المشفرة (ncRNAs) التي لا تُترجم إلى بروتين ، ولكن بدلاً من ذلك لها وظائف مباشرة (مثل الأدوار في ترجمة البروتين ، وتكرار الحمض النووي ، وربط الحمض النووي الريبي ، وتنظيم النسخ ). تؤثر العديد من ncRNAs على الحالات المرضية ، بما في ذلك السرطان وأمراض القلب والأوعية الدموية والأمراض العصبية.
قواعد بيانات النسخ
تولد دراسات النسخ كميات كبيرة من البيانات التي لها تطبيقات محتملة تتجاوز بكثير الأهداف الأصلية للتجربة. على هذا النحو ، قد يتم إيداع البيانات الخام أو المعالجة في قواعد البيانات العامة لضمان فائدتها للمجتمع العلمي الأوسع. على سبيل المثال ، اعتبارًا من 2018 ، احتوى Gene Expression Omnibus على ملايين التجارب.
| اسم | مضيف | البيانات | وصف |
|---|---|---|---|
| Omnibus التعبير الجيني | NCBI | ميكروأري RNA-Seq | أول قاعدة بيانات transcriptomics لقبول البيانات من أي مصدر. قدم MIAME و MINSEQE معايير المجتمع التي تحدد الفوقية التجربة اللازمة لضمان تفسير وفعال التكرار . |
| ArrayExpress | ENA | ميكروأري | يستورد مجموعات البيانات من Gene Expression Omnibus ويقبل عمليات الإرسال المباشرة. يتم تخزين البيانات المعالجة والبيانات الوصفية للتجربة في ArrayExpress ، بينما يتم الاحتفاظ بقراءات التسلسل الأولي في ENA. يتوافق مع معايير MIAME و MINSEQE. |
| أطلس التعبير | EBI | ميكروأري RNA-Seq | قاعدة بيانات التعبير الجيني الخاصة بالأنسجة للحيوانات والنباتات. يعرض التحليلات الثانوية والتصور ، مثل الإثراء الوظيفي لمصطلحات Gene Ontology أو مجالات InterPro أو المسارات. روابط لبيانات وفرة البروتين عند توفرها. |
| جينيفستيجاتور | برعاية خاصة | ميكروأري RNA-Seq | يحتوي على تنظيمات يدوية لمجموعات بيانات النسخ العامة ، مع التركيز على البيانات الطبية والبيولوجية النباتية. يتم تطبيع التجارب الفردية عبر قاعدة البيانات الكاملة للسماح بمقارنة التعبير الجيني عبر تجارب متنوعة. تتطلب الوظائف الكاملة شراء ترخيص ، مع وصول مجاني إلى وظائف محدودة. |
| المرجع | DDBJ | الكل | نسخ الإنسان والفأر والجرذان من 40 عضوًا مختلفًا. يتم تصور التعبير الجيني كخرائط حرارية معروضة على تمثيلات ثلاثية الأبعاد للهياكل التشريحية. |
| NONCODE | noncode.org | RNA- تسلسل | الحمض النووي الريبي غير المشفر (ncRNAs) باستثناء الحمض الريبي النووي الريبي والـ rRNA. |
NCBI - المركز الوطني لمعلومات التكنولوجيا الحيوية ؛ EBI - المعهد الأوروبي للمعلوماتية الحيوية ؛ DDBJ - بنك بيانات DNA الياباني ؛ ENA - أرشيف النوكليوتيدات الأوروبي ؛ MIAME - الحد الأدنى من المعلومات حول تجربة ميكروأري ؛ MINSEQE - الحد الأدنى من المعلومات حول تجربة SEQuencing عالية الإنتاجية للنيوكليوتيدات.
انظر أيضًا
المراجع
ملاحظات
قراءة متعمقة
-
"Transcriptomics technologies". PLOS Computational Biology. ج. 13 ع. 5: e1005457. مايو 2017. Bibcode:2017PLSCB..13E5457L. doi:10.1371/journal.pcbi.1005457. PMID 28545146.
{{استشهاد بدورية محكمة}}: الوسيط غير المعروف|PMCID=تم تجاهله (يقترح استخدام|pmc=) (مساعدة) - تحليل النسخ المقارن في الوحدة المرجعية في علوم الحياة
- البرمجيات المستخدمة في النسخ: